
 | Oussema Dhaouadi, Johannes Meier, Jacques Kaiser, Daniel Cremers WACV 2026 Project Page | Paper We introduce GrounDiff, a diffusion-based method that generates DTMs from DSMs by iteratively removing non-ground structures, achieving up to 93% lower error than prior learning-based approaches, and present PrioStitch and GrounDiff+ for scalable high-resolution terrain generation and smooth road reconstruction with up to 81% lower distance error. |
 | Oussema Dhaouadi, Riccardo Marin, Johannes Meier, Jacques Kaiser, Daniel Cremers NeurIPS 2025 (Oral) Project Page | Paper | Data | Github Repo We introduce OrthoLoC, the first large-scale UAV localization dataset with 16,425 images from Germany and the U.S., paired with orthophotos and digital surface models (DSMs) to enable benchmarking under domain shifts, and propose AdHoP, a refinement method that improves feature matching accuracy by up to 95% and reduces translation error by 63%, advancing lightweight high-precision aerial localization without GNSS or large 3D models. |
 | Jingchao Xie*, Oussema Dhaouadi*, Weirong Chen, Johannes Meier, Jacques Kaiser, Daniel Cremers IV 2025 (Oral - Best Paper Award) Project Page | Paper | Github Repo | Poster We propose CoProU-VO, an unsupervised visual odometry framework that propagates and combines uncertainty across temporal frames to robustly filter dynamic objects, leveraging vision transformers to jointly learn depth, uncertainty, and poses, and achieving superior performance on KITTI and nuScenes, especially in challenging dynamic and highway scenarios. |
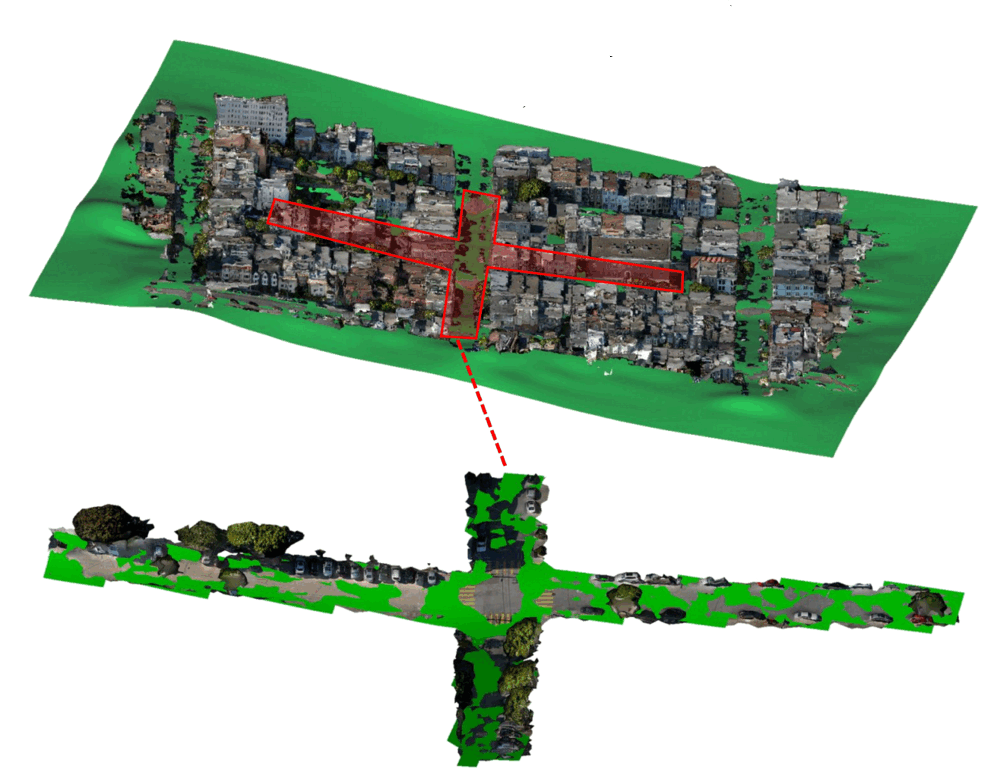 | Oussema Dhaouadi, Johannes Meier, Jacques Kaiser, Daniel Cremers IV 2025 Project Page | Paper | Data | Poster We present FlexRoad, the first framework for smooth and accurate road surface reconstruction using NURBS fitting with Elevation-Constrained Spatial Road Clustering, and introduce the GeoRoad Dataset (GeRoD) for benchmarking, demonstrating that FlexRoad outperforms existing methods across diverse datasets and terrains while robustly handling noise and input variability. |
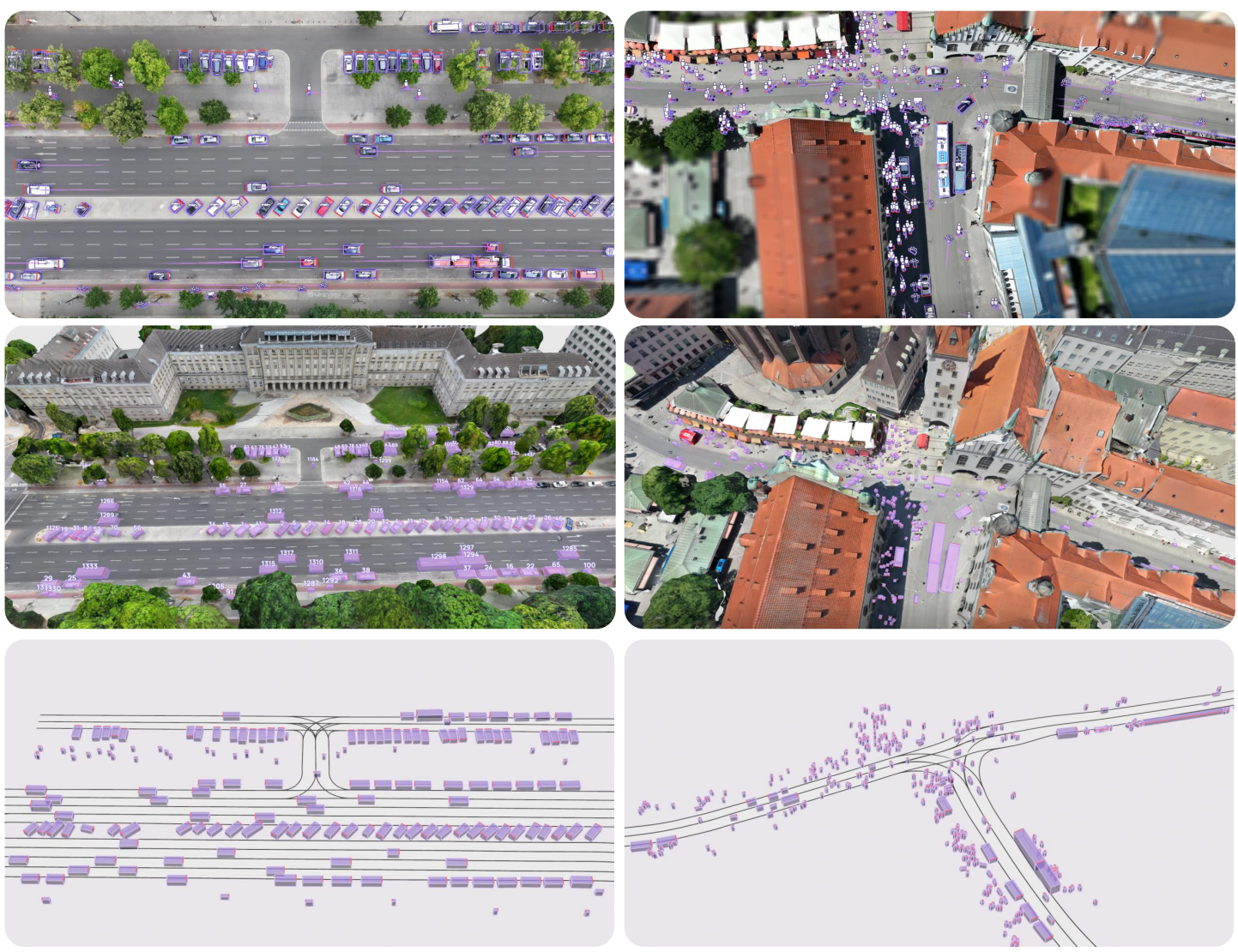 | Oussema Dhaouadi*, Johannes Meier*, Louis Inchingolo*, Luca Wahl, Jacques Kaiser, Luca Scalerandi, Nick Wandelburg, Zhuolun Zhou, Nijanthan Berinpanathan, Holger Banzhaf, Daniel Cremers IV 2025 Project Page | Paper | Data | Poster We introduce DSC3D, a large-scale, occlusion-free 3D trajectory dataset captured via a monocular drone tracking pipeline, featuring over 175,000 trajectories of 14 traffic participant types across diverse urban and suburban scenarios, designed to enhance autonomous driving systems with detailed environmental representations and improved obstacle interaction modeling. |
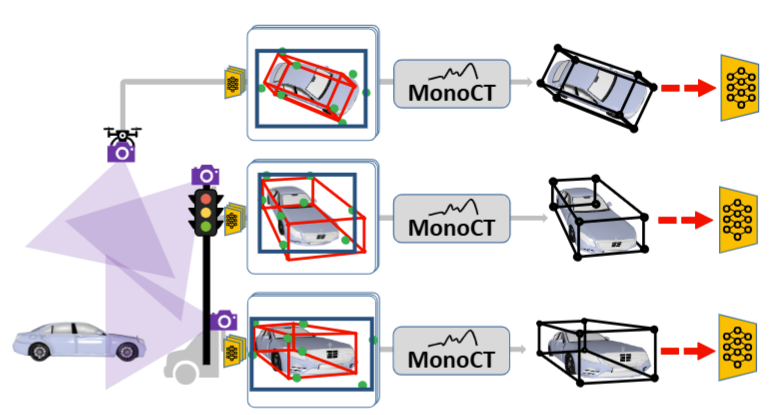 | Johannes Meier*, Louis Inchingolo*, Oussema Dhaouadi, Yan Xia*, Jacques Kaiser, Daniel Cremers ICRA 2025 (Oral) Paper We address monocular 3D object detection across diverse sensors and environments with MonoCT, an unsupervised domain adaptation method that uses Generalized Depth Enhancement, Pseudo Label Scoring, and Diversity Maximization to generate high-quality pseudo labels, achieving up to 21% improvement over prior state-of-the-art methods across six benchmarks. |
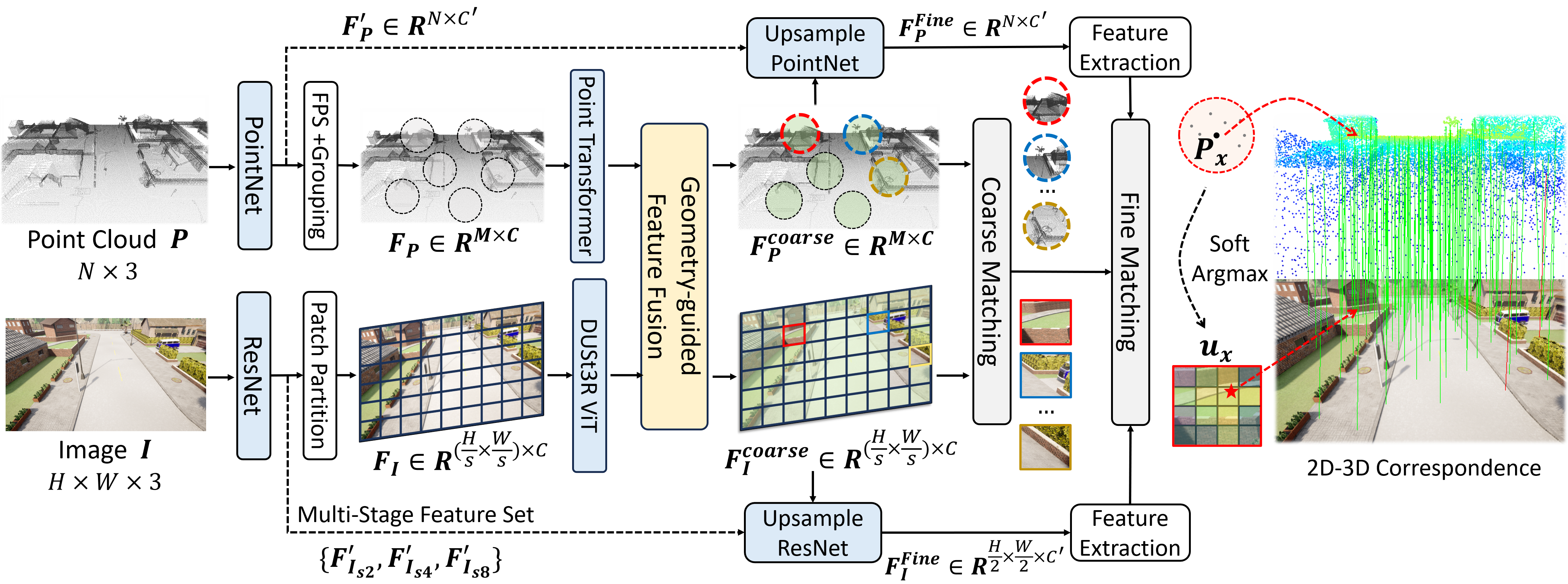 | Yan Xia*, Yunxiang Lu*, Rui Song, Oussema Dhaouadi, João F. Henriques, Daniel Cremers ICCV 2025 Project Page | Paper We tackle traffic camera localization in 3D maps by introducing TrafficLoc, a coarse-to-fine image-to-point cloud registration method with Geometry-guided Attention Loss, Inter-intra Contrastive Learning, and Dense Training Alignment, alongside the Carla Intersection dataset, achieving up to 86% improvement over prior methods and new state-of-the-art performance on KITTI and NuScenes for both in-vehicle and traffic cameras. |
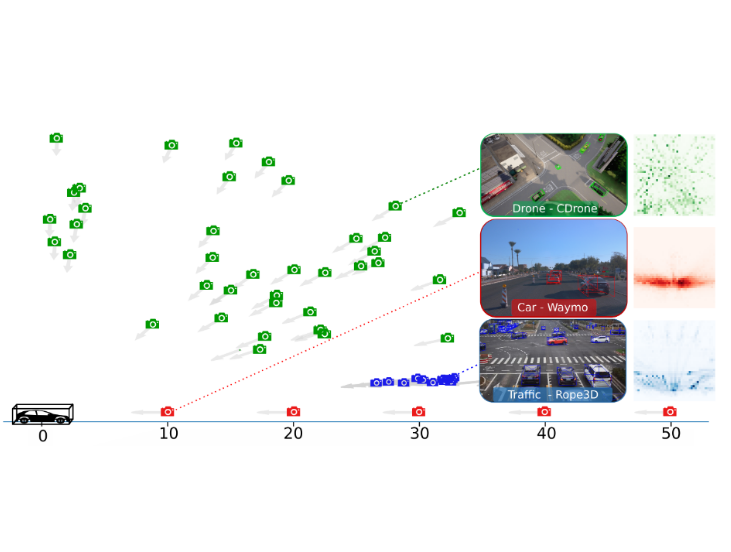 | Johannes Meier, Luca Scalerandi, Oussema Dhaouadi, Jacques Kaiser, Nikita Araslanov, Daniel Cremers GCPR 2024 (Oral) Project Page | Github Repo | Paper | Data We introduce the CARLA Drone (CDrone) dataset to expand 3D detection benchmarks with diverse camera perspectives and propose GroundMix, a ground-based 3D-consistent augmentation pipeline, demonstrating that prior methods struggle across these views while our approach significantly improves detection accuracy across both synthetic and real-world datasets. |
 | Ahmet Firintepe, Oussema Dhaouadi, Alain Pagani, Didier Stricker ISMAR-Adjunct 2021 Paper | IEEE We introduce CapsPose, a novel capsule-network-based 6-DoF pose estimator, and compare head pose versus AR glasses pose estimation, showing that AR glasses pose is generally more accurate, while CapsPose significantly outperforms existing methods on the HMDPose dataset. |