
About me
Hi, I’m Oussema Dhaouadi, a PhD student at the Technical University of Munich in the Computer Vision Group led by Prof. Daniel Cremers. I am currently a visiting researcher at ETH Zürich in the Computer Vision and Geometry Group led by Prof. Marc Pollefeys. During my PhD, I worked in collaboration with DeepScenario on 3D reconstruction and localization.
Before starting my PhD, I was a Machine Learning Engineer at Knowlix GmbH, where I built automated solutions for paperwork. I received my Master’s degree with high distinction in Electrical Engineering and Information Technology from TUM. I completed my thesis at the BMW Group Research and Technology Center under the supervision of Dr. Ahmet Firintepe and Prof. Eckehard Steinbach and spent a semester abroad at NTU Singapore. I also hold a Bachelor’s degree in Electrical Engineering and Information Technology from TUM, where I completed my Bachelor’s thesis under the supervision of Alexander Kuhn and Prof. Alois Knoll. During my studies, I gained additional experience at Fujitsu and Rohde & Schwarz.









News
- 2026.01: Started a research visit at ETH Zürich in the Computer Vision and Geometry Group led by Prof. Marc Pollefeys.
- 2025.11: completed my role as a computer vision scientist at DeepScenario.
- 2025.11: GrounDiff accepted at WACV 2026.
- 2025.09: CoProU-VO received best paper award at GCPR 2025.
- 2025.09: OrthoLoC accepted as an oral presentation at NeurIPS 2025.
- 2025.07: CoProU-VO accepted as an oral presentation at GCPR 2025.
- 2025.06: TrafficLoc accepted at ICCV 2025.
- 2025.03: Two papers, DSC3D and FlexRoad, accepted at IV 2025.
- 2025.01: MonoCT accepted at ICRA 2025.
- 2024.08: CDrone accepted at GCPR 2024.
- 2023.12: Started PhD at TUM Computer Vision Group under Prof. Daniel Cremers.
- 2021.11: Completed the TUM Skills Excellence program.
- 2021.09: Joined Knowlix GmbH as Machine Learning Engineer.
- 2021.07: Earned M.Sc. in Electrical Engineering and Information Technology from TUM.
- 2021.03: Internship at BMW Group; co-authored CapsPose, accepted at ISMAR-Adjunct 2021.
- 2020.09: Started research internship at BMW Group.
- 2020.01–2020.05: Semester abroad at NTU Singapore.
- 2018.07: Started as Software Developer at Rohde & Schwarz GmbH after leaving Fujitsu.
- 2017.03: Began role as Hardware Developer at Fujitsu.
- 2015.10: Started B.Sc. in Electrical Engineering and Information Technology at TUM.
Publications
 | Oussema Dhaouadi, Johannes Meier, Jacques Kaiser, Daniel Cremers WACV 2026 Project Page | Paper We introduce GrounDiff, a diffusion-based method that generates DTMs from DSMs by iteratively removing non-ground structures, achieving up to 93% lower error than prior learning-based approaches, and present PrioStitch and GrounDiff+ for scalable high-resolution terrain generation and smooth road reconstruction with up to 81% lower distance error. |
 | Oussema Dhaouadi, Riccardo Marin, Johannes Meier, Jacques Kaiser, Daniel Cremers NeurIPS 2025 (Oral) Project Page | Paper | Data | Github Repo We introduce OrthoLoC, the first large-scale UAV localization dataset with 16,425 images from Germany and the U.S., paired with orthophotos and digital surface models (DSMs) to enable benchmarking under domain shifts, and propose AdHoP, a refinement method that improves feature matching accuracy by up to 95% and reduces translation error by 63%, advancing lightweight high-precision aerial localization without GNSS or large 3D models. |
 | Jingchao Xie*, Oussema Dhaouadi*, Weirong Chen, Johannes Meier, Jacques Kaiser, Daniel Cremers IV 2025 (Oral - Best Paper Award) Project Page | Paper | Github Repo | Poster We propose CoProU-VO, an unsupervised visual odometry framework that propagates and combines uncertainty across temporal frames to robustly filter dynamic objects, leveraging vision transformers to jointly learn depth, uncertainty, and poses, and achieving superior performance on KITTI and nuScenes, especially in challenging dynamic and highway scenarios. |
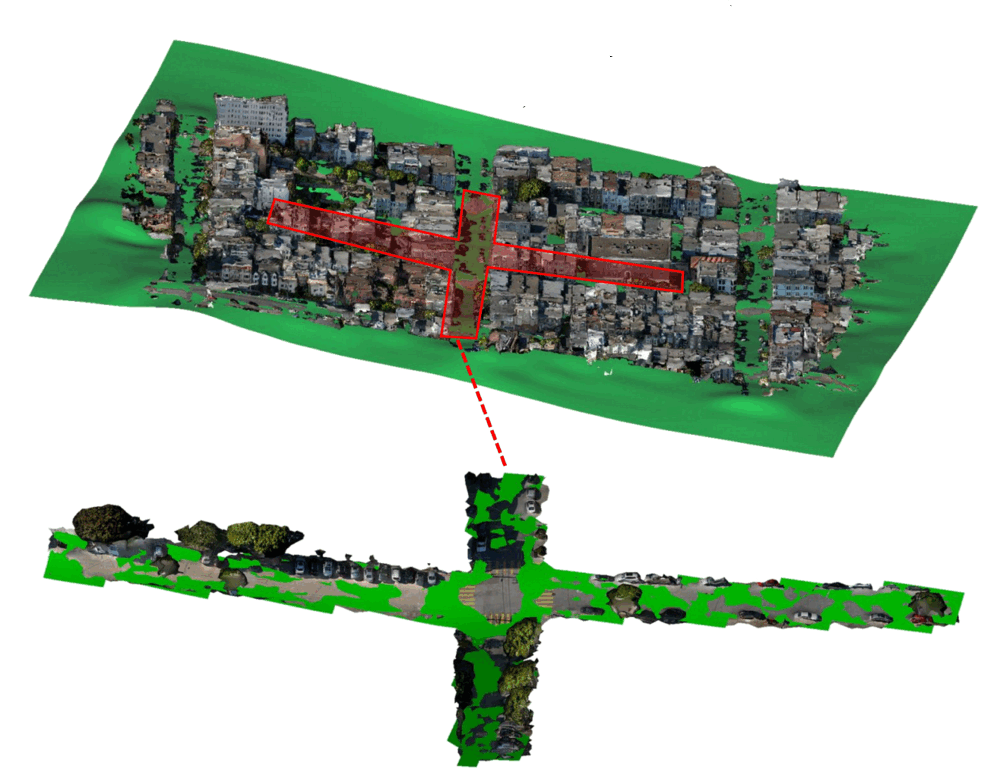 | Oussema Dhaouadi, Johannes Meier, Jacques Kaiser, Daniel Cremers IV 2025 Project Page | Paper | Data | Poster We present FlexRoad, the first framework for smooth and accurate road surface reconstruction using NURBS fitting with Elevation-Constrained Spatial Road Clustering, and introduce the GeoRoad Dataset (GeRoD) for benchmarking, demonstrating that FlexRoad outperforms existing methods across diverse datasets and terrains while robustly handling noise and input variability. |
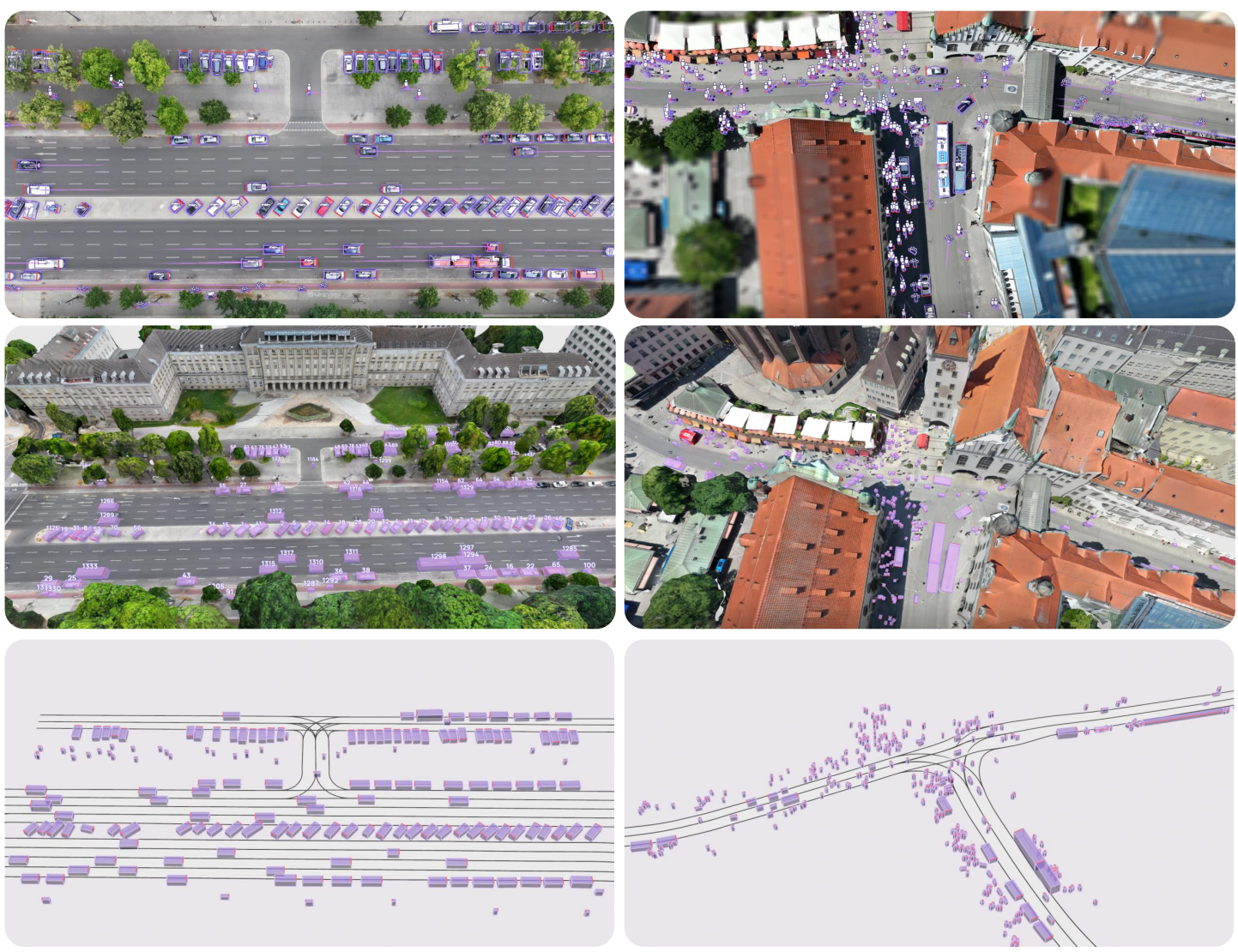 | Oussema Dhaouadi*, Johannes Meier*, Louis Inchingolo*, Luca Wahl, Jacques Kaiser, Luca Scalerandi, Nick Wandelburg, Zhuolun Zhou, Nijanthan Berinpanathan, Holger Banzhaf, Daniel Cremers IV 2025 Project Page | Paper | Data | Poster We introduce DSC3D, a large-scale, occlusion-free 3D trajectory dataset captured via a monocular drone tracking pipeline, featuring over 175,000 trajectories of 14 traffic participant types across diverse urban and suburban scenarios, designed to enhance autonomous driving systems with detailed environmental representations and improved obstacle interaction modeling. |
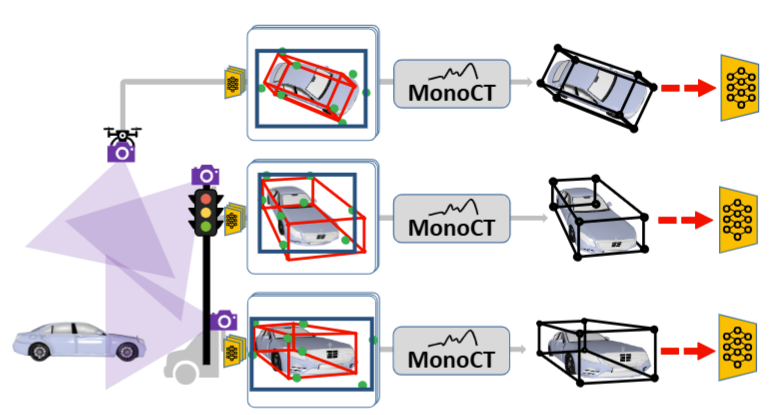 | Johannes Meier*, Louis Inchingolo*, Oussema Dhaouadi, Yan Xia*, Jacques Kaiser, Daniel Cremers ICRA 2025 (Oral) Paper We address monocular 3D object detection across diverse sensors and environments with MonoCT, an unsupervised domain adaptation method that uses Generalized Depth Enhancement, Pseudo Label Scoring, and Diversity Maximization to generate high-quality pseudo labels, achieving up to 21% improvement over prior state-of-the-art methods across six benchmarks. |
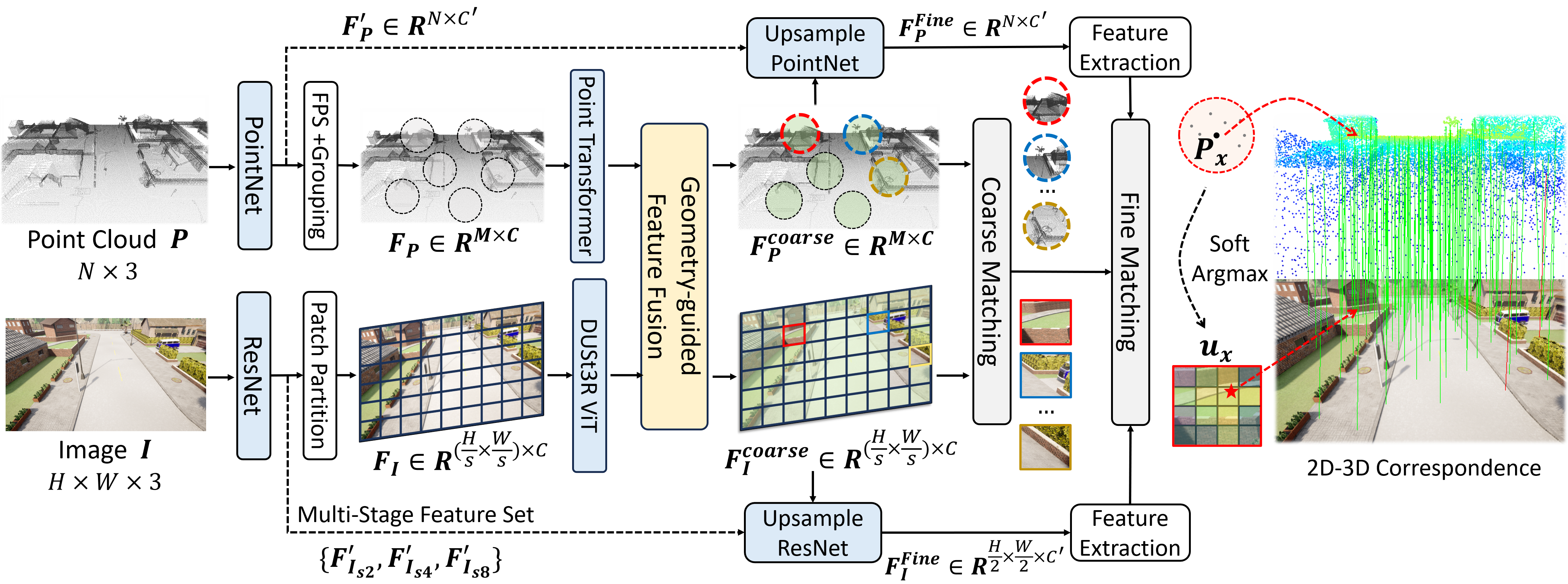 | Yan Xia*, Yunxiang Lu*, Rui Song, Oussema Dhaouadi, João F. Henriques, Daniel Cremers ICCV 2025 Project Page | Paper We tackle traffic camera localization in 3D maps by introducing TrafficLoc, a coarse-to-fine image-to-point cloud registration method with Geometry-guided Attention Loss, Inter-intra Contrastive Learning, and Dense Training Alignment, alongside the Carla Intersection dataset, achieving up to 86% improvement over prior methods and new state-of-the-art performance on KITTI and NuScenes for both in-vehicle and traffic cameras. |
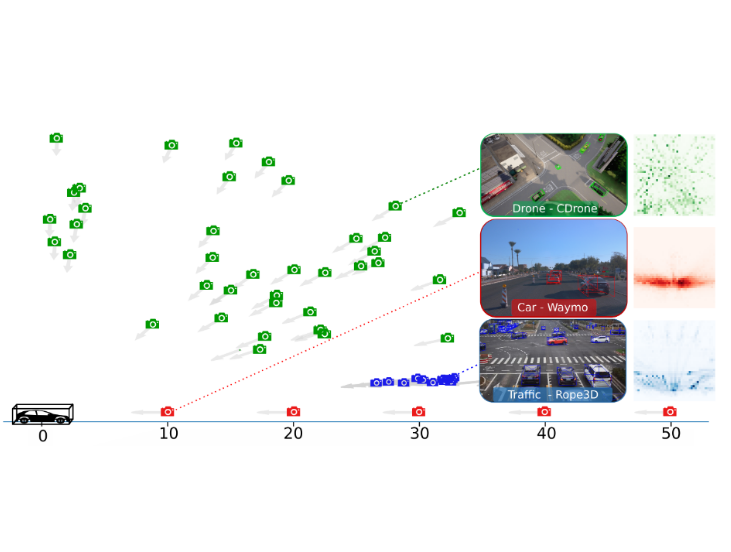 | Johannes Meier, Luca Scalerandi, Oussema Dhaouadi, Jacques Kaiser, Nikita Araslanov, Daniel Cremers GCPR 2024 (Oral) Project Page | Github Repo | Paper | Data We introduce the CARLA Drone (CDrone) dataset to expand 3D detection benchmarks with diverse camera perspectives and propose GroundMix, a ground-based 3D-consistent augmentation pipeline, demonstrating that prior methods struggle across these views while our approach significantly improves detection accuracy across both synthetic and real-world datasets. |
 | Ahmet Firintepe, Oussema Dhaouadi, Alain Pagani, Didier Stricker ISMAR-Adjunct 2021 Paper | IEEE We introduce CapsPose, a novel capsule-network-based 6-DoF pose estimator, and compare head pose versus AR glasses pose estimation, showing that AR glasses pose is generally more accurate, while CapsPose significantly outperforms existing methods on the HMDPose dataset. |
Other Projects
 | 2020 Github Repo | Report We introduce SeqCapsGAN, a stylized image captioning framework that combines Generative Adversarial Networks and Capsule Networks to generate human-like captions with sentiment, outperforming baseline models on key evaluation metrics. |
 | 2020 Github Repo | Report We introduce EMG-Caps, a framework for hand gesture classification using Capsule Networks on sEMG signals from the NinaPro DB5 dataset, demonstrating that CapsNets outperform conventional classifiers and other deep learning methods—achieving up to 93.27% accuracy across 53 hand movements. |
 | 2019 Github Repo | Report We performed data acquisition and preprocessing, designed and evaluated classification systems using both conventional and neural network–based pattern recognition methods in TensorFlow and Keras, and implemented a real-time operating 6-DoF robot arm. |
 | 2019 Github Repo We implemented trajectory planning algorithms (RRT/RRT*) in C++, simulated and evaluated their performance in both simple and challenging scenarios, and conducted real-world testing on the NAO robot using ROS. |
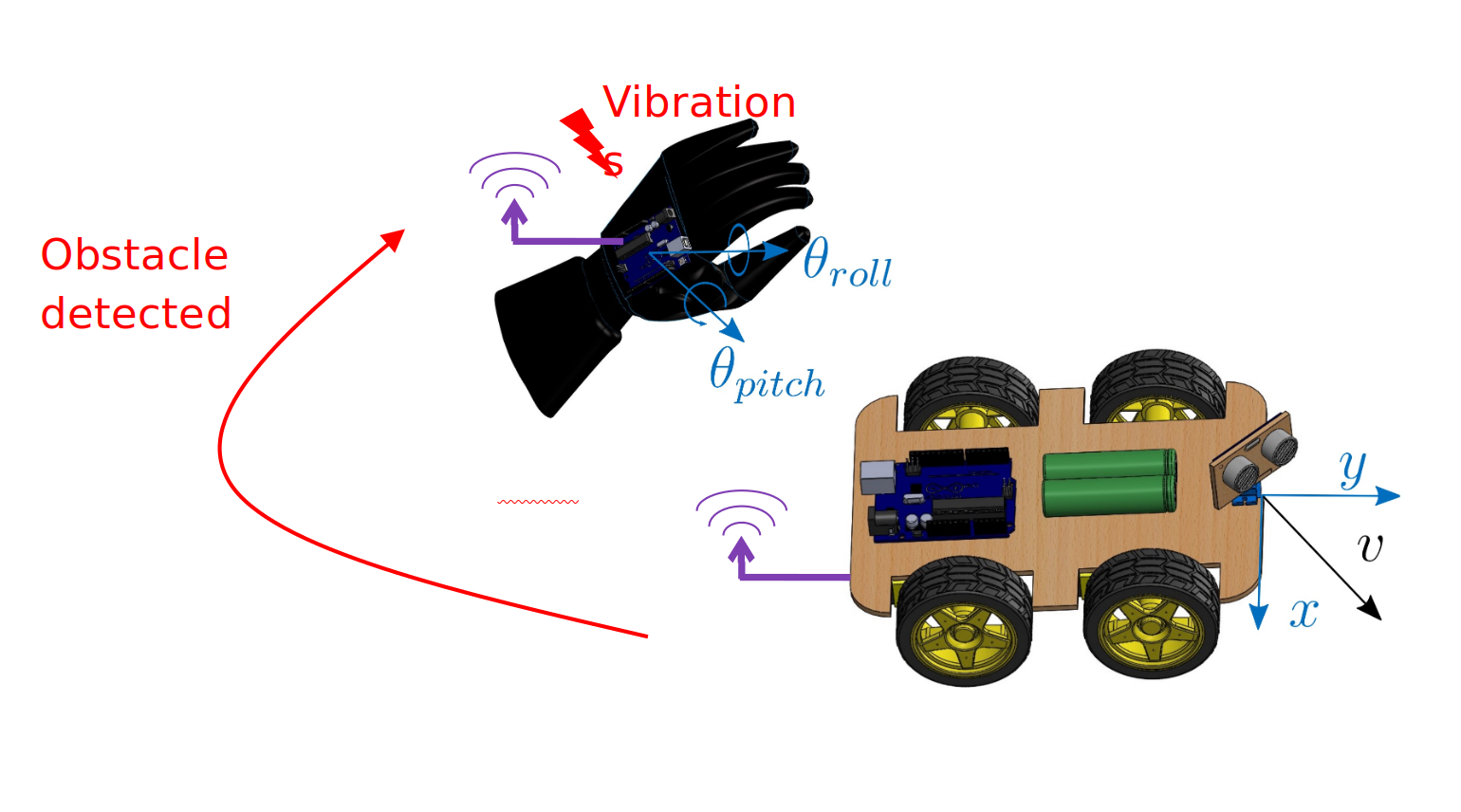 | 2019 Github Repo We developed Hand Gesture Controlled Obstacle Avoiding Robot, implementing embedded programming in C++ on an Atmega328P microcontroller, sensor signal processing with a 6DoF IMU, ultrasonic and IR sensors, actuation control for servos, gear motors, and vibration motors, and a custom communication protocol for a radio transmitter/receiver module. |
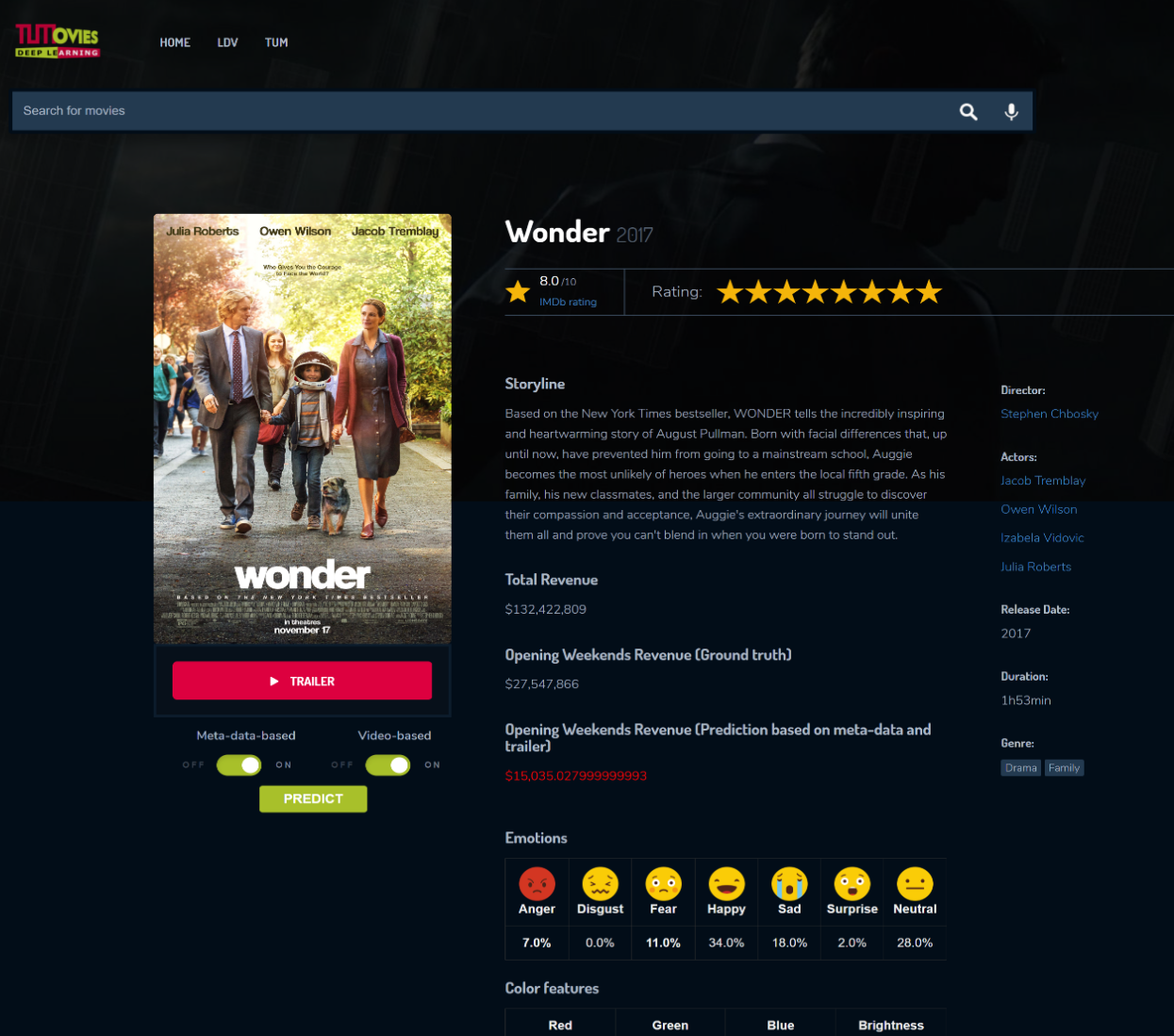 | 2019 Github Repo In this project, we presented a system for predicting opening weekend box office sales from movie trailers by combining metadata (e.g., actors, studio, genre) with audio-visual features (e.g., spectrograms, colors, emotions), and implemented a frontend that enables users to run predictions on arbitrary YouTube trailers. |
 | 2018 Github Repo This thesis introduces CapsGAN, a generative modeling framework that integrates capsule networks into the GAN discriminator to better preserve spatial relationships, evaluates different CapsGAN architectures and routing algorithms, and demonstrates that dynamic routing improves training stability and sample quality compared to standard GAN approaches. |
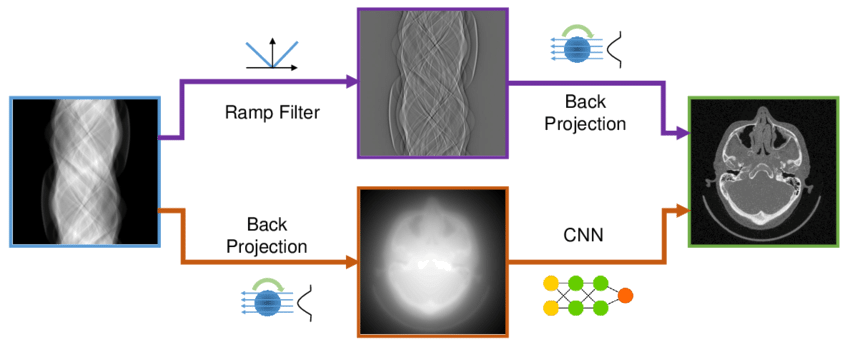 | 2018 Github Repo In this project, we develop a deep learning–based learnable filter to enhance the CT image reconstruction pipeline for improved image quality and reconstruction accuracy. |